
{kind=link}
SMALLM: a Local Small Model Augmented a Cloud-based Large Language Model for Chinese Named Entity Recognition in Low-resource Industries
Complex & Intelligent Systems, 2025
引用方式: Yang, J., Yang, Z.*, Wu, C.*, Guo, Y., Li, X., Lin, J. (2025). SMALLM: a Local Small Model Augmented a Cloud-based Large Language Model for Chinese Named Entity Recognition in Low-resource Industries. Complex & Intelligent Systems, 11, 460. doi: 10.1007/s40747-025-02074-6 http://doi.org/10.1007/s40747-025-02074-6
摘要
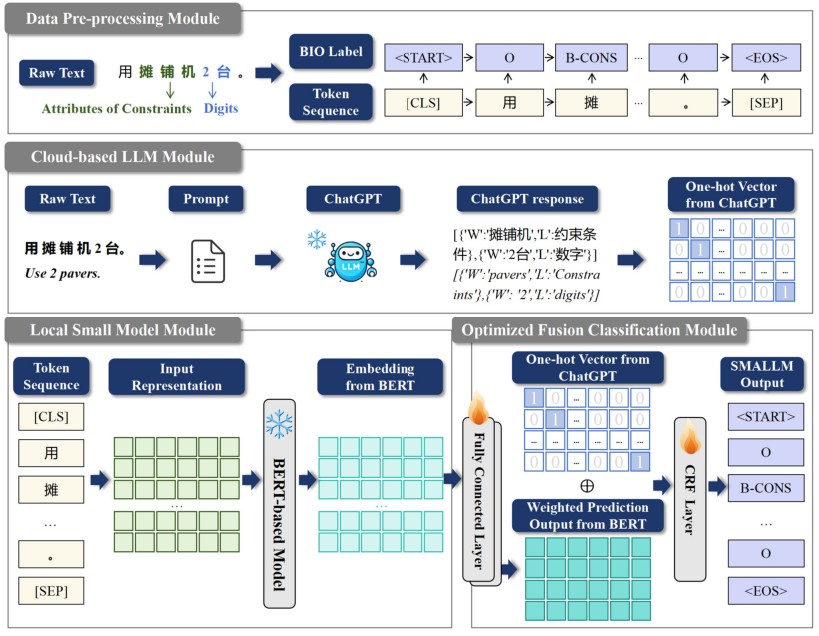
尽管基于云的商用大型语言模型(LLMs)在多种自然语言处理(NLP)任务中实现了最先进(SOTA)的性能和前沿的零样本学习能力,但其在命名实体识别(NER)任务上的表现仍显著低于有监督基线模型。通用领域的 NER 已取得显著成果,但专业领域的 NER 因数据稀缺和计算资源有限,仍面临诸多挑战。为此,本研究提出一种新型 NER 框架 “SMALLM”,以端到端方式集成基于 BERT 的本地小模型,用于增强最先进 LLM(ChatGPT)的性能。SMALLM 兼具小模型与 LLM 的优势,通过少样本学习成为领域专家,仅需更新基于 BERT 的本地模型中数十万个参数,且所需训练数据极少 —— 这大幅降低了计算需求,实现快速训练并减少对数据的依赖。此外,该框架针对 ChatGPT 等闭源 LLM 的限制提供了解决方案:将其响应转换为独热向量,以用于后续优化与集成。在建筑、CCKS2019 - 军事、CCKS2020 - 医疗三个中文专业领域 NER 数据集上的实验表明,SMALLM 使 ChatGPT 的性能分别提升 28.80%、13.48% 和 48.37%,且在低资源场景下持续优于主流模型。
Although the cloud-based commercial Large Language Models (LLMs) have achieved state-of-the-art (SOTA) performances and cutting-edge zero-shot learning abilities on a variety of Natural Language Processing (NLP) tasks, their performance on Named Entity Recognition (NER) is still significantly below supervised baselines. While NER in the universal domain has achieved remarkable success, NER in specialized industries continues to face challenges due to the scarcity of data and computational resource. To address these issues, this study proposes “SMALLM”, a novel NER framework that integrates a local BERT-based model to augment the performance of the state-of-the-art LLM, ChatGPT, in an end-to-end manner. By leveraging both the strengths of the small model and the LLM, SMALLM acts as a domain expert through few-shot learning. SMALLM updates only hundreds of thousands of parameters in the local BERT-based model with minimal training data. This significantly reduces computational demands, enables fast training and minimizes reliance on data. Additionally, our framework provides a solution to the constraints posed by closed-source LLMs like ChatGPT converting their responses into one-hot vectors for subsequent optimization and integration. Through experiments on three industrial Chinese NER (CNER) datasets—Construction, CCKS2019- Military, and CCKS2020-Clinic—SMALLM enhances the performance of ChatGPT, achieving improvements of 28.80%, 13.48%, and 48.37%, respectively. Additionally, SMALLM consistently surpasses mainstream models in low-resource settings.
The work described in this paper is supported by grants from Shenzhen Science Fund for Excellent Young Scholars (Grant No. RCYX20221008093036022), Chinese Academy of Sciences President’s International Fellowship Initiative Grant (No.2025PVA0112), Guangdong Special Support Plan Science and Technology Innovation Young Top-notch Talents (No.2023TQ07L745), Shenzhen-Hong Kong joint funding project (A)(No. SGDX20230116092053005), the Science and Technology Project of Shenzhen (No.CJGJZD20220517141405012), the Youth Innovation Promotion Association CAS (Grant No. 2021358), Shenzhen Excellent Innovative Talents (RCYX20221008093036022), and the Guangdong Special Support Plan Science and Technology Innovation Young Topnotch Talents (No.2023TQ07L745).
发表评论