
{kind=link}
SMALLM: a Local Small Model Augmented a Cloud-based Large Language Model for Chinese Named Entity Recognition in Low-resource Industries
Complex & Intelligent Systems, 2025
Recommended citation: Yang, J., Yang, Z.*, Wu, C.*, Guo, Y., Li, X., Lin, J. (2025). SMALLM: a Local Small Model Augmented a Cloud-based Large Language Model for Chinese Named Entity Recognition in Low-resource Industries. Complex & Intelligent Systems, 11, 460. doi: 10.1007/s40747-025-02074-6 http://doi.org/10.1007/s40747-025-02074-6
Abstract
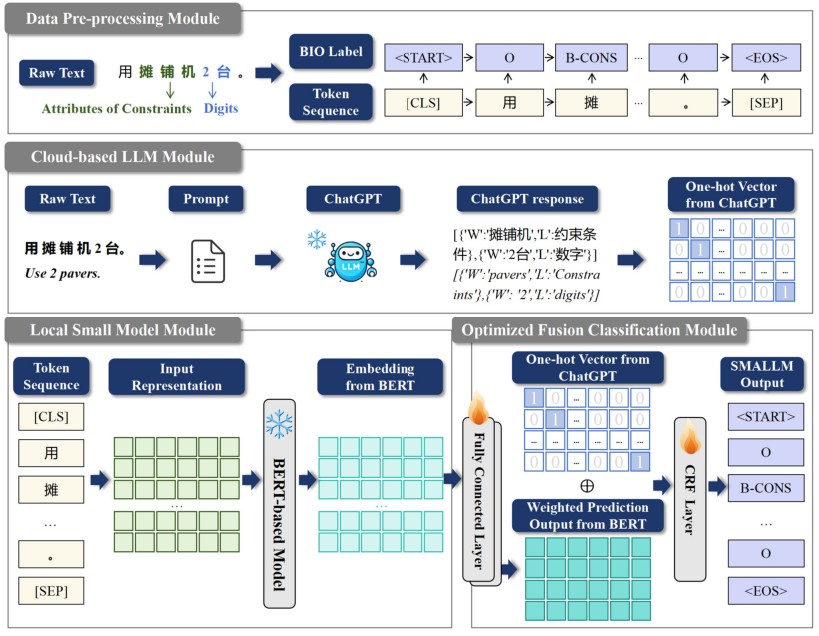
Although the cloud-based commercial Large Language Models (LLMs) have achieved state-of-the-art (SOTA) performances and cutting-edge zero-shot learning abilities on a variety of Natural Language Processing (NLP) tasks, their performance on Named Entity Recognition (NER) is still significantly below supervised baselines. While NER in the universal domain has achieved remarkable success, NER in specialized industries continues to face challenges due to the scarcity of data and computational resource. To address these issues, this study proposes “SMALLM”, a novel NER framework that integrates a local BERT-based model to augment the performance of the state-of-the-art LLM, ChatGPT, in an end-to-end manner. By leveraging both the strengths of the small model and the LLM, SMALLM acts as a domain expert through few-shot learning. SMALLM updates only hundreds of thousands of parameters in the local BERT-based model with minimal training data. This significantly reduces computational demands, enables fast training and minimizes reliance on data. Additionally, our framework provides a solution to the constraints posed by closed-source LLMs like ChatGPT converting their responses into one-hot vectors for subsequent optimization and integration. Through experiments on three industrial Chinese NER (CNER) datasets—Construction, CCKS2019- Military, and CCKS2020-Clinic—SMALLM enhances the performance of ChatGPT, achieving improvements of 28.80%, 13.48%, and 48.37%, respectively. Additionally, SMALLM consistently surpasses mainstream models in low-resource settings.
The work described in this paper is supported by grants from Shenzhen Science Fund for Excellent Young Scholars (Grant No. RCYX20221008093036022), Chinese Academy of Sciences President’s International Fellowship Initiative Grant (No.2025PVA0112), Guangdong Special Support Plan Science and Technology Innovation Young Top-notch Talents (No.2023TQ07L745), Shenzhen-Hong Kong joint funding project (A)(No. SGDX20230116092053005), the Science and Technology Project of Shenzhen (No.CJGJZD20220517141405012), the Youth Innovation Promotion Association CAS (Grant No. 2021358), Shenzhen Excellent Innovative Talents (RCYX20221008093036022), and the Guangdong Special Support Plan Science and Technology Innovation Young Topnotch Talents (No.2023TQ07L745).
Leave a Comment